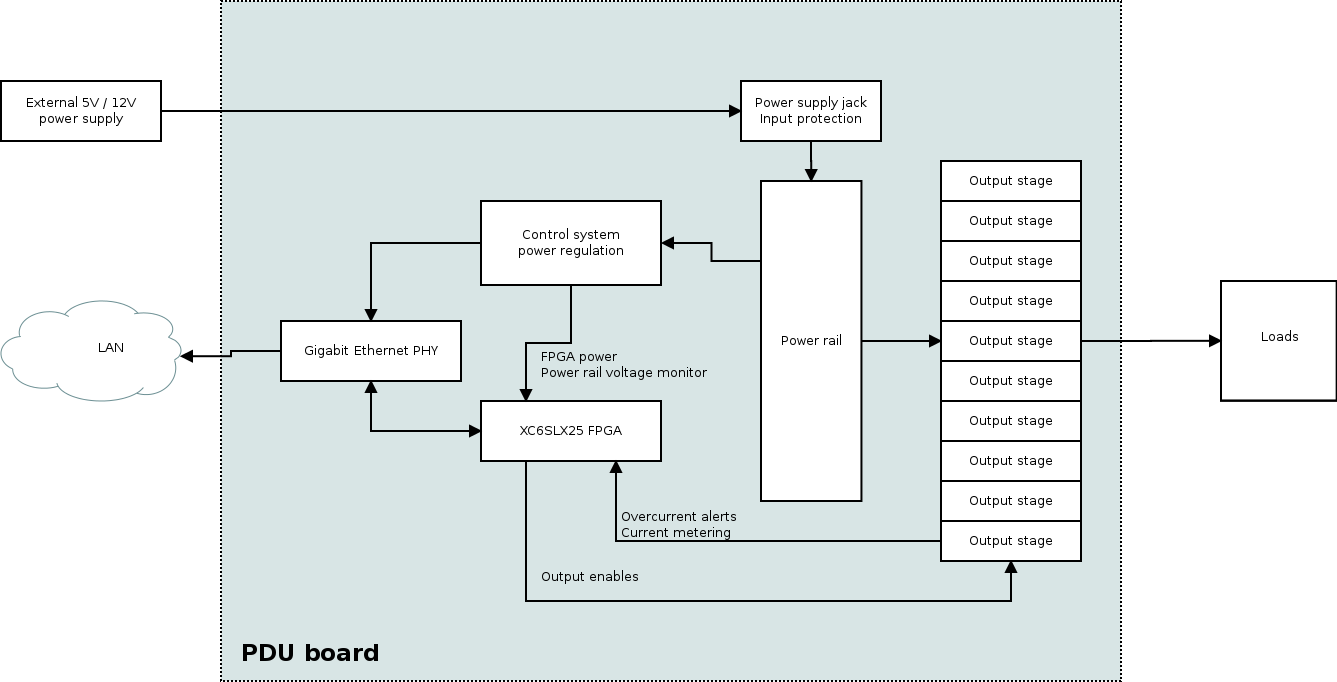
After my last post on the PDU, I began doing more exhaustive testing. I left Munin polling all of the stats every 5 minutes and kept the GUI open for maybe half an hour, turning channels on and off, and everything seemed fine...
Then I went away to do something else, came back to my desk, and saw that the GUI had frozen. The board wasn't responding to ping (or any network activity at all), and I had no idea why.
Other than confirming that the interconnect fabric was still working (by resolving the addresses of a few cores by the name server) there wasn't a ton I could do without adding some diagnostic code.
I then resynthesized the FPGA netlist with the gdb bridge enabled on the CPU. (The FPGA is packed pretty full; I don't leave the bridge in all the time because it substantially increases place-and-route runtime and sometimes requires decreasing the maximum clock rate). After waiting around half an hour for the build to complete I reloaded the FPGA with the new code, fired up the GUI, and went off to tidy up the lab.
After checking in a couple of times and not seeing a hang, I finally got it to crash a couple hours later. A quick inspection in gdb suggested that the CPU was executing instruction normally, had not segfaulted, and there was no sign of trouble. In each case the program counter was somewhere in RecvRPCMessage(), as would be expected when the message loop was otherwise idle. So what was the problem?
The next step was to remove the gdb bridge and insert a logic analyzer core. (As mentioned above the FPGA is filled to capacity and it's not possible to use both at the same time without removing application logic.)
After another multi-hour build-and-wait-for-hang cycle, I managed to figure out that the CPU was popping the inbound-message FIFO correctly and seemed to be still executing instructions. None of the error flags were set.
I thought for a while and decided to check the free-memory-page counter in the allocator. A few hours later, I saw that the free-page count was zero... a telltale sign of a memory leak.
I wasted untold hours and many rebuild cycles trying to find the source of the leak before sniffing the RPC link between the CPU and the network. As soon as I saw packets arriving and not being sent, I knew that the leak wasn't the problem. It was just another symptom. The CPU was getting stuck somewhere and never processing new Ethernet frames; as soon as enough frames had arrived to fill all memory then all processing halted.
Unfortunately, at this point I still had no idea what was causing the bug. I could reliably trigger the logic analyzer after the bug had happened and the CPU was busy-waiting (by triggering when free_page_count hit 1 or 0) but had no way to tell what led up to it.
RPC packet captures taken after the fault condition showed that the new-frame messages from the Ethernet MAC were arriving to the CPU just fine. The CPU could be clearly seen popping them from the hardware FIFO and storing them in memory immediately.
Eventually, I figured out just what looked funny about the RPC captures: the CPU was receiving RPC messages, issuing memory reads and writes, but never sending any RPC messages whatsoever. This started to give me a hint as to what was happening.
I took a closer look at the execution traces and found that the CPU was sitting in a RecvRPCMessage() call until a message showed up, then PushInterrupt()ing the message and returning to the start of the loop.
/**
@brief Performs a function call through the RPC network.
@param addr Address of target node
@param callnum The RPC function to call
@param d0 First argument (only low 21 bits valid)
@param d1 Second argument
@param d2 Third argument
@param retval Return value of the function
@return zero on success, -1 on failure
*/
int __attribute__ ((section (".romlibs"))) RPCFunctionCall(
unsigned int addr,
unsigned int callnum,
unsigned int d0,
unsigned int d1,
unsigned int d2,
RPCMessage_t* retval)
{
//Send the query
RPCMessage_t msg;
msg.from = 0;
msg.to = addr;
msg.type = RPC_TYPE_CALL;
msg.callnum = callnum;
msg.data[0] = d0;
msg.data[1] = d1;
msg.data[2] = d2;
SendRPCMessage(&msg);
//Wait for a response
while(1)
{
//Get the message
RecvRPCMessage(retval);
//Ignore anything not from the host of interest; save for future processing
if(retval->from != addr)
{
//TODO: Support saving function calls / returns
//TODO: Support out-of-order function call/return structures
if(retval->type == RPC_TYPE_INTERRUPT)
PushInterrupt(retval);
continue;
}
//See what it is
switch(retval->type)
{
//Send it again
case RPC_TYPE_RETURN_RETRY:
SendRPCMessage(&msg);
break;
//Fail
case RPC_TYPE_RETURN_FAIL:
return -1;
//Success, we're done
case RPC_TYPE_RETURN_SUCCESS:
return 0;
//We're not ready for interrupts, save them
case RPC_TYPE_INTERRUPT:
PushInterrupt(retval);
break;
default:
break;
}
}
}
I spent most of a day repeatedly running the board until it hung to collect a sampling of different failures. A pattern started to emerge: addr was always 0x8003, the peripheral controller. This module contains a couple of peripherals that weren't big enough to justify the overhead of a full RPC router port on their own:
- One ten-signal bidirectional GPIO port (debug/status LEDs plus a few reserved for future expansion)
- One 32-bit timer with interrupt on overflow (used for polling environmental sensors for fault conditions, as well as socket timeouts)
- One I2C master port (for talking to the DACs)
- Three SPI master ports (for talking to the ADCs)
After not seeing anything obviously amiss in the peripheral controller Verilog, I added one last bit of instrumentation: logging the last message successfully processed by the peripheral controller.
The next time the board froze, the CPU was in the middle of the first PERIPH_SPI_RECV_BYTE call in the function below (reading one channel of a MCP3204 quad ADC) but the peripheral controller was idle and had most recently processed the PERIPH_SPI_SEND_BYTE call on the line before.
unsigned int ADCRead(unsigned char spi_channel, unsigned char adc_channel)
{
//Get the actual sensor reading
RPCMessage_t rmsg;
unsigned char opcode = 0x30;
opcode |= (adc_channel << 1);
opcode <<= 1;
RPCFunctionCall(g_periphAddr, PERIPH_SPI_ASSERT_CS, 0, spi_channel, 0, &rmsg);
RPCFunctionCall(g_periphAddr, PERIPH_SPI_SEND_BYTE, opcode, spi_channel, 0, &rmsg); //Three dummy bits first
//then request read of CH0
//(single ended)
RPCFunctionCall(g_periphAddr, PERIPH_SPI_RECV_BYTE, 0, spi_channel, 0, &rmsg); //Read first 8 data bits
unsigned int d0 = rmsg.data[0];
RPCFunctionCall(g_periphAddr, PERIPH_SPI_RECV_BYTE, 0, spi_channel, 0, &rmsg); //Read next 4 data bits
//followed by 4 garbage bits
unsigned int d1 = rmsg.data[0];
RPCFunctionCall(g_periphAddr, PERIPH_SPI_DEASSERT_CS, 0, spi_channel, 0, &rmsg);
return ((d0 << 4) & 0xFF0) | ( (d1 >> 4) & 0xF);
}
Operating under the assumption that my well-tested interconnect IP didn't have a bug that could make it drop packets randomly, the only remaining explanation was that the peripheral controller was occasionally ignoring an incoming RPC.
I took another look at the code and found the bug near the end of the main state machine:
//Wait for RPC transmits to finish STATE_RPC_TXHOLD: begin if(rpc_fab_tx_done) begin rpc_fab_rx_done <= 1; state <= STATE_IDLE; end end //end STATE_RPC_TXHOLD
I was setting the "done" flag to pop the receive buffer every time I finished sending a message... without checking that I was sending it in response to another message. The only time this was ever untrue is when sending a timer overflow interrupt.
As a result, if a new message arrived at the peripheral controller between the start and end of sending the timer overflow message, it would be dropped. The window for doing this is only four clock cycles every 50ms, which explains the extreme rarity of the hang.
EDIT: Just out of curiosity I ran a few numbers to calculate the probability of a hang:
- At the 30 MHz CPU speed I was using for testing, the odds of any single RPC transaction hanging are 1 in 375,000.
- Reading each of the 12 ADC channels requires 5 SPI transactions, or 60 in total. The odds of at least one of these triggering a hang is 1 in 6250.
- The client GUI polls at 4 Hz.
- The chance of a hang occurring within the first 15 minutes of runtime is 43%.
- The chance of a hang occurring within the first half hour is 68%.
- There is about a 10% chance that the board will run for over an hour without hanging, and yet the bug is still there.